Guide to DevOps and DevOps Tools

Hey, folks in this blog you will understand what DevOps is and where DevOps comes into the picture in SDLC etc... You might be overwhelmed that there are a lot of tools and technologies that are there to learn in DevOps. In this blog, you will get a high-level overview of where these tools fit in and where DevOps comes into the picture of SDLC
To better comprehend, we will first look at it from the perspective of an individual before moving on to how an organisation might approach it.so consider this blog as part 1
Let's say you decide to create a website that enables users to reserve movie tickets in advance. You start coding in your preferred editor, and after an hour, the initial version of your website is complete. so you have the code on your computer and the website is accessible only on your localhost 8080, and you discovered a means to do that by putting your application on a server. This server can be either a real server or a virtual server.

As a result, you cannot simply copy a piece of code and expect it to work; you must configure the system in order for it to function. For example, if the code was written in Python, it requires Python dependencies such as libraries, packages, etc. You must also configure them in order for it to function when running on a server.

When everything is finished, you have the application running on your server, the server has an IP address, and you have now purchased a domain for your application so that it is now accessible to everyone. You developed your code on a laptop, which becomes your developer environment, and the server you hosted your application on becomes your production environment.
In order to run code as an application by an end user, it must currently be in executable format. Building code is the process of translating code from text format to binary or executable format, and there are tools available such as gradle or maven for this. The deploy stage is a straightforward three-step process where the executable is moved to the production environment and run in production after it has been built.
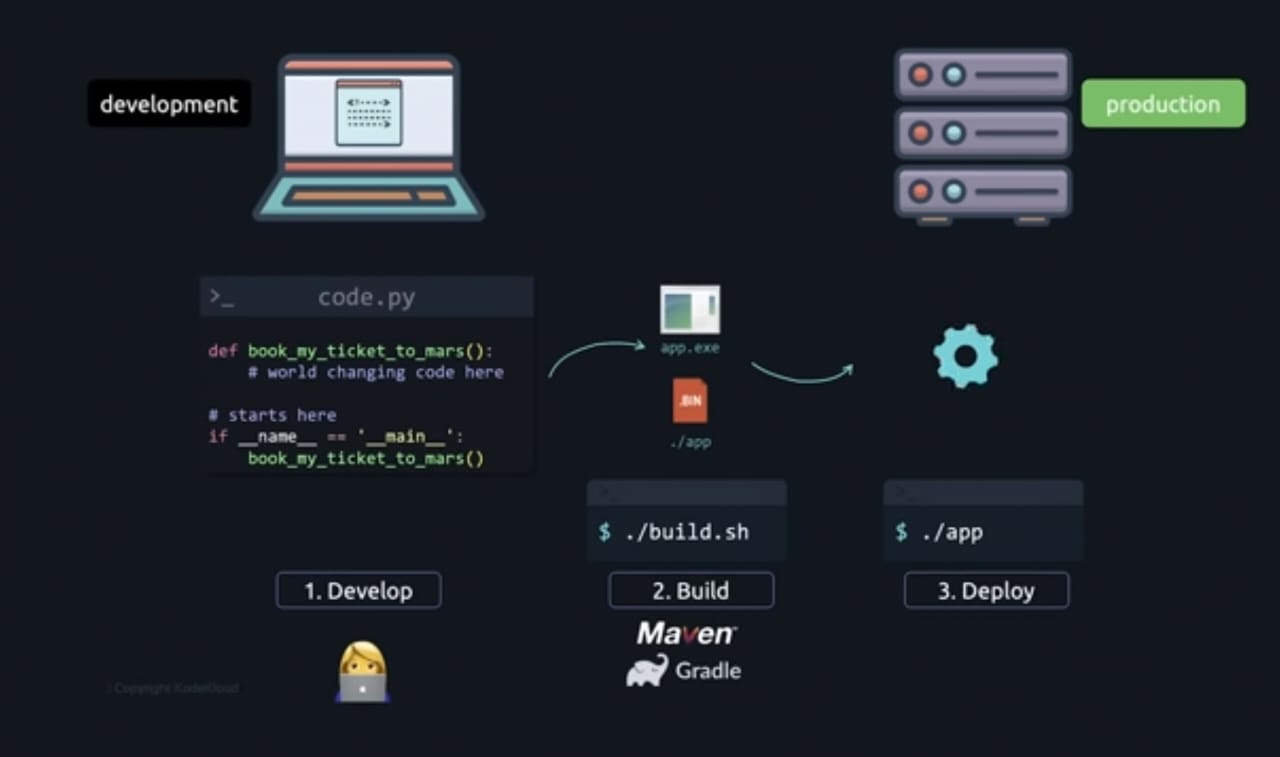
It's just a broad overview; there are many other options to do it.
As a result, your programme was widely used, and you had countless numbers of daily visitors. Users advised you to include many features in your application, but you are now unable to accomplish it on your own therefore you have also hired pals to help
Git & Github
As everyone is working separately, the base code has been copied across all development environments. Every time they are ready, they rush over each other to get to the centre. Conflict arises when people are concurrently working on the same files, and you need a workable solution. Git is the technology for that. Since everyone has installed and configured git on their computers, it will be simple to find the most recent git code and allows all developers to collaborate on the same application that is running simultaneously. The central Hub is a cloud-based platform that acts as a repository, and the primary hub uses the git pull order to make its modifications and push by the git push command to return it.

In summary, GitHub is a git-based publicly accessible repository of code where you push your code, and it has a web interface where you can invite new developers, manage your project, manage issues with your project, add documentation to your code, etc. Now that there are four developers and git and GitHub are in place, the development issues are solved.
CI/CD pipeline
The previous workflow required developing code in your development environment, building the code to an executable package, and then deploying it to production. However, with multiple developers, the code needs to be built with the changes contributed by all of the developers, so building on the laptop itself no longer works as an individual's laptop may not be able to handle all of the changes, it makes sense to move the build operation to a dedicated build server that gets the latest version of the code and builds it before moving into production.
As a result, it is risky to push new versions into production because they may have introduced issues or broken something that was previously working, thus we must also test them in a test environment. This is how the workflow looks. Currently, every developer creates code in their development environment on their laptops and pushes it to GitHub. You then manually copy the code to your build server, where it is built into an executable. You then manually copy the executable to the test server, where you test the application to ensure that it functions as intended and that no new bugs are introduced. Finally, you manually copy the executable to the production environment and deploy it. This is a labour-intensive process.
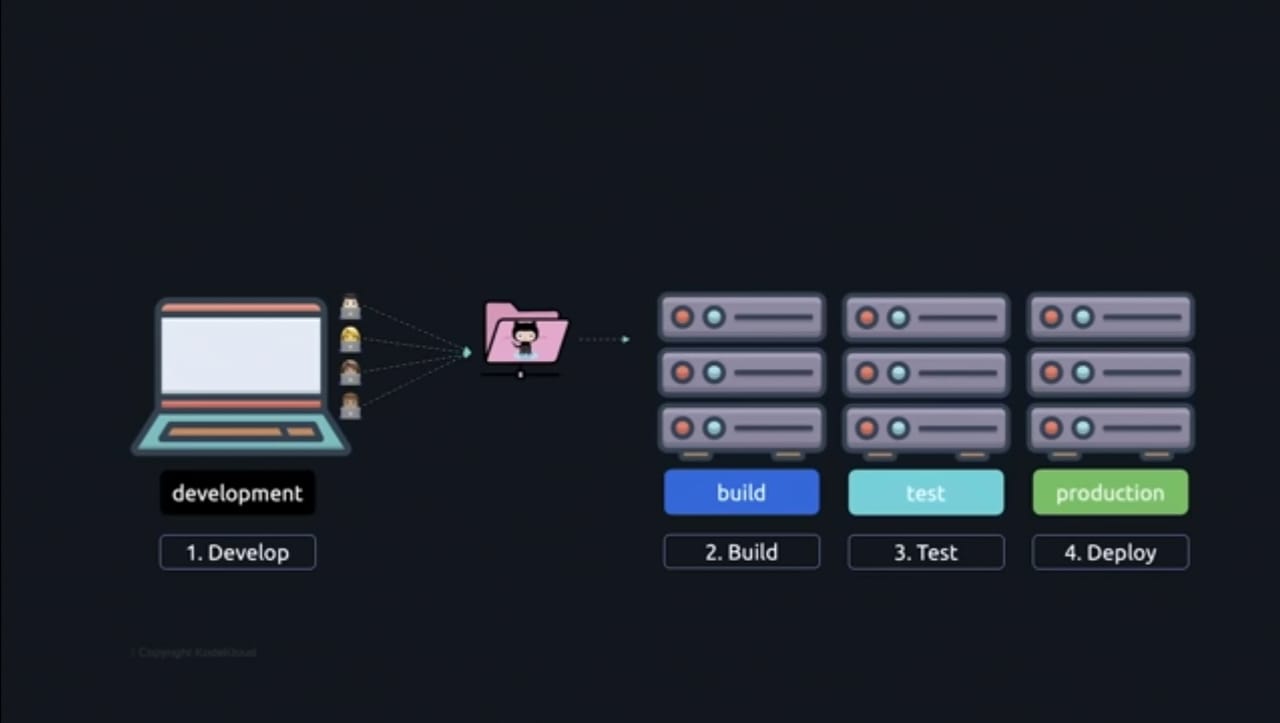
It calls for several physical procedures. You decide to push all new code containing new features to the production environment once a week, but users and your fellow developers don't like that because some minor features can already be pushed to production and don't necessarily need to wait until the end of the week, and the manual deployment process itself takes a week to complete on its own. As the code base and features expand, you want to be able to release features more quickly. Comes into a picture CICD.
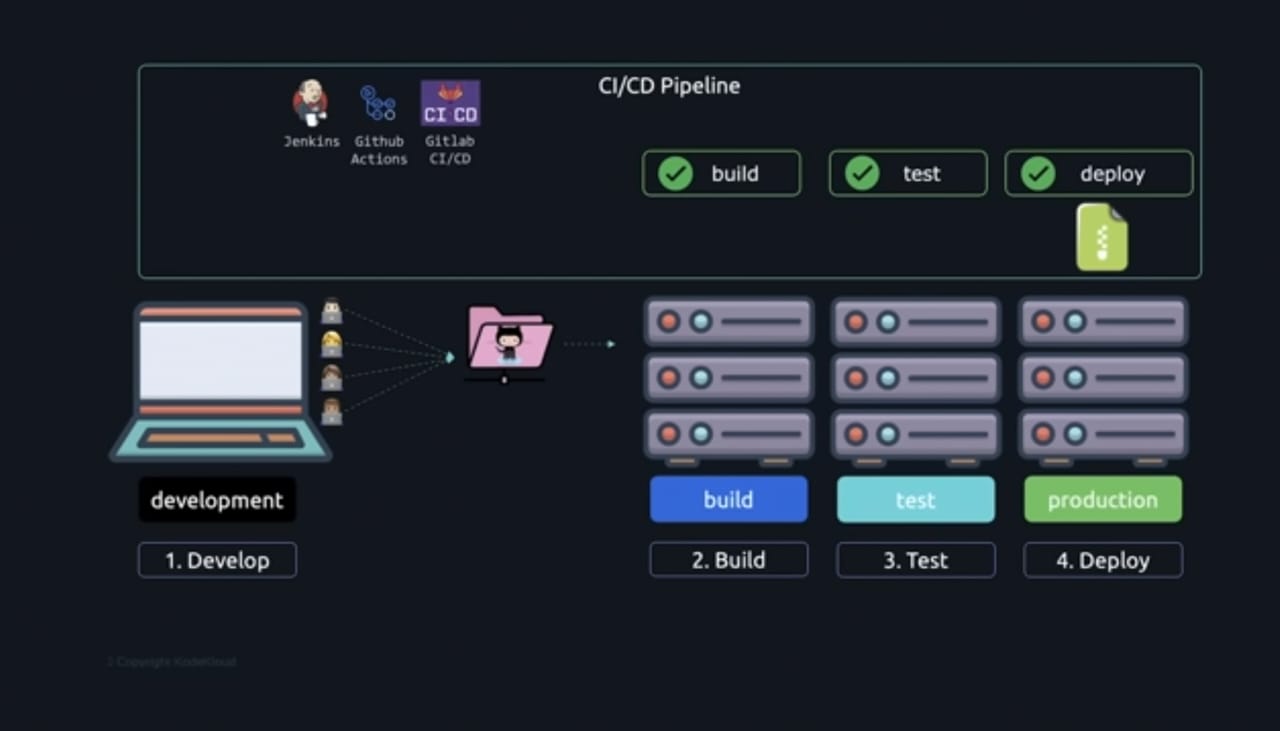
Continuous Integration and Continuous Delivery (CICD) refer to the use of tools like Jenkins, GitHub activities, and GitLab CCI can help you automate these manual tasks and create a pipeline using one of these tools so that whenever code is pushed, it is automatically fetched from the GitHub repository to the build server, built, and then the executable is automatically moved to the test server and tested, after which it is moved to the production server and deployed.
Now that changes, features, and bug fixes can flow through the pipeline more quickly and be delivered more frequently with less manual work, you and your team can ship features more quickly and make users happy. Now that Git, GitHub, and CICD pipelines are in place, our team can make changes to our application and seamlessly deploy them to production servers, but it's still not entirely seamless.
Docker
Keep in mind that the dependencies and libraries we discussed earlier—the ones that are necessary for the applications to run on any system—need to be configured the same way on the servers, which means that if a new package is required, this needs to be configured accordingly, and because installing and configuring new packages on all the servers where this code run is still a manual process if one of these packages is not installed or configured correctly, the software won't function properly and may exhibit unexpected behaviour on various systems. This is where containers come in. Containers help package the application and its dependencies into an image.
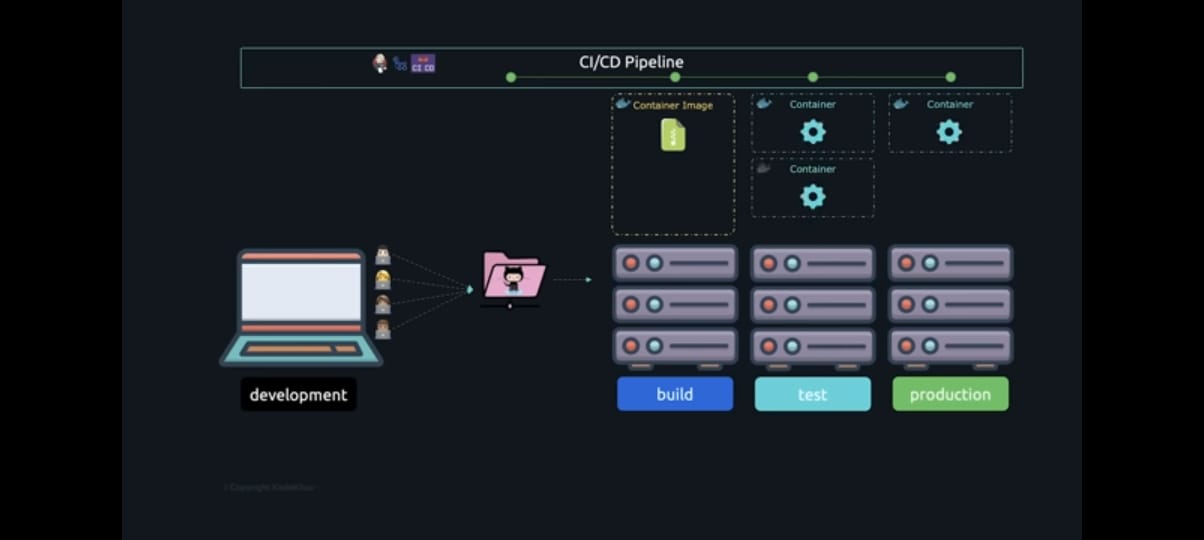
One tool that makes working with containers possible is Docker. With Docker, a developer can create a Docker file that lists the dependencies. This Docker file can then be used during the build to create an image, which can then be run on any server using a straightforward Docker run command. The main functionality of a container is that it enables isolation between applications.
Kubernetes
So let's focus on the production side of things. As our user base expands, we want to be able to add more servers and run our programme on each of them. Currently, we only have one production server. We only need to run containers on those servers now that we have them, but how do you do that correctly so that containers are spun up when the user base increases and destroyed when the load decreases? How can you make sure that a container is automatically brought back online if it fails as well? comes into the picture of Kubernetes. Ensure optimal resource use by managing resources on the underlying service, and automatically scaling containers, along with the supporting infrastructure based on need and resource management and foundational service to guarantee the ideal use of resources.

Terraform
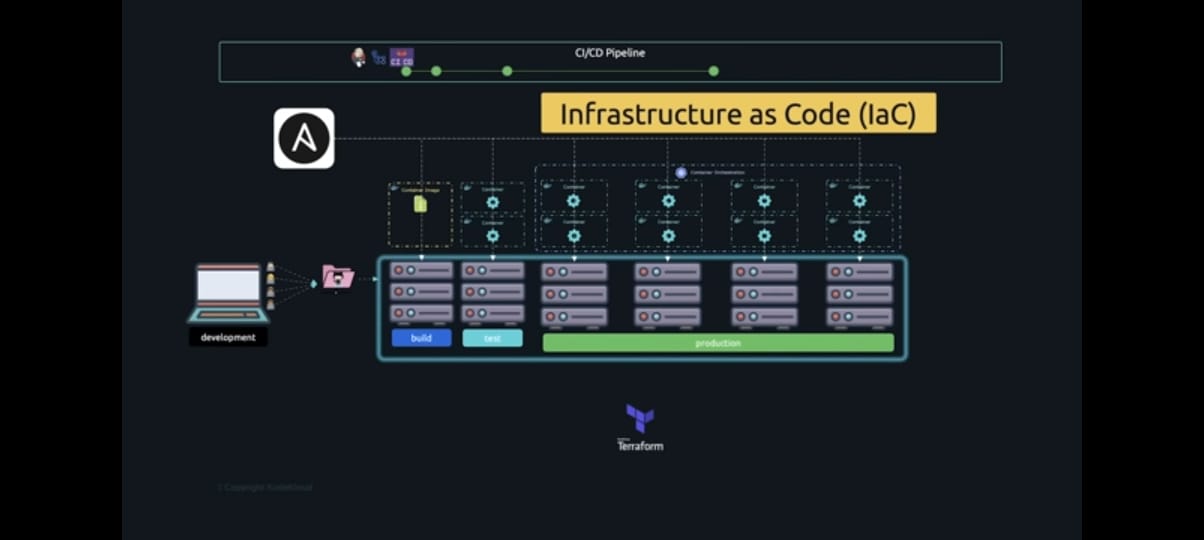
Now that we have developers pushing code to a central GitHub repository, the CI CD pipeline pulls the code to the build server, builds it to Docker images, and then uses those images to test the application in the test environment before deploying them in a production environment as containers by Kubernetes. However, the underlying infrastructure is still a major challenge because each time a new server is provisioned, it needs to be set up the same way as the others to avoid conflicts. and there might be some kernel settings or other software that needs to be pre-configured on it like the docker runtime or the necessary Kubernetes packages, all of which need to have the same configuration, so this is going to be one big challenge if you have to click through the cloud platform GUI every time a server needs to be provisioned. This can take a lot of time and can lead to human errors in misconfiguring infrastructure, resulting in having to rebuild.
The state of a server is defined by configuring a terraform manifest file that looks like this. Terraform automates the provisioning and configuration of servers regardless of what cloud platforms they are on and it ensures that the server is configured are always in the same state if someone manually changes a configuration on these servers without using Terraform it changes it back to ensure that the states defined is preserved. Yes, it looks like code because it is code, which is why it is known as infrastructure as code. Here is an excerpt from a Terraform manifest file that lists servers and their configuration.

Once the servers are provisioned, the configuration of these servers can be automated by tools like ansible so while Terraform is more of an infrastructure-as-code approach, ansible is more of an IAAS approach. All of the infrastructure configuration, including the virtual machines, storage buckets, VPC, etc., is now stored in the form of code and is stored in source code repositories that way it can be considered as any other code and be tracked if changes are needed then make changes to the code
Ansible
While Terraform is used primarily for provisioning and de-provisioning infrastructure, Ansible is used for post-configuration tasks like installing the software and configuring them on those servers. Ansible uses code to configure servers; these playbooks are stored in the source code repository on GitHub. .
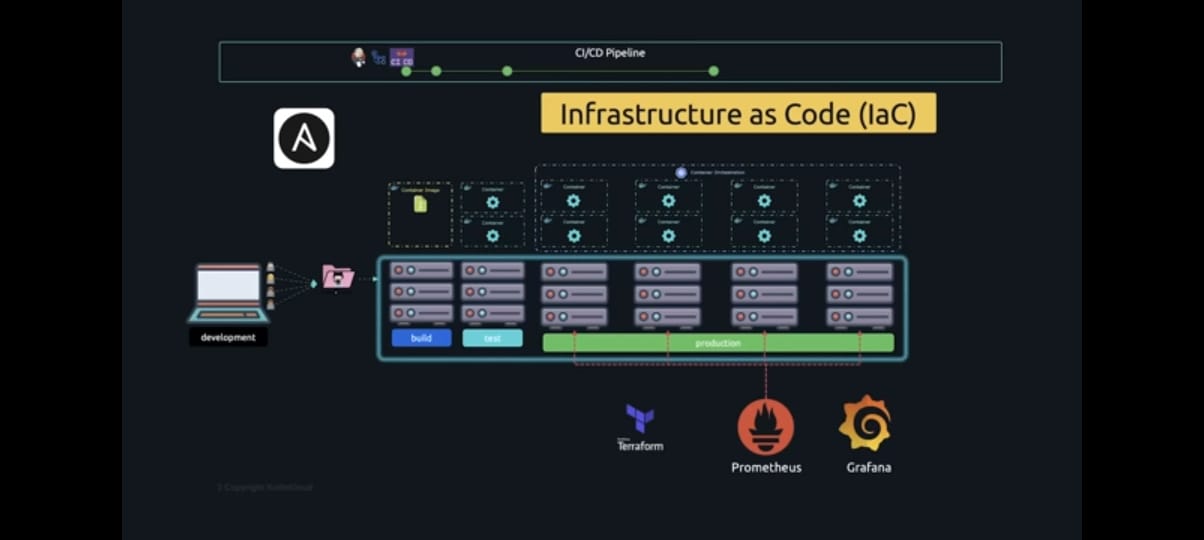
Prometheus
However, provisioning is not all we want to do; we also want to maintain it. identify which processes are producing higher usage using the memory consumption monitor, etc... Prometheus is one such tool that can help with this. Prometheus gathers data or metrics from several servers and stores it centrally, but we also want to be able to graphically display those metrics, which is where tools like Grafana come in.
Grafana
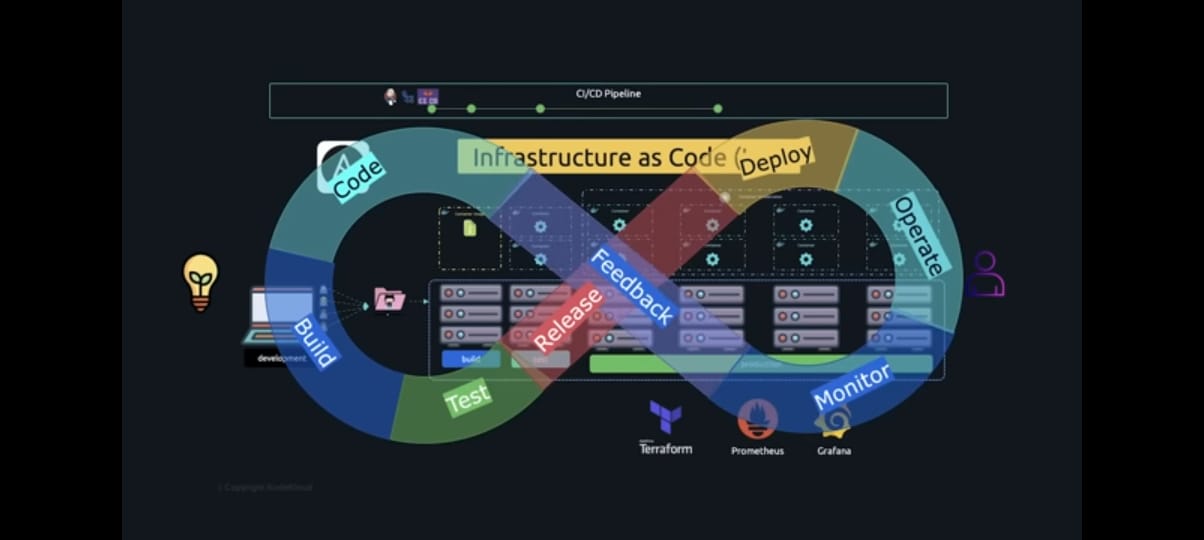
By transforming the data collected by Prometheus into charts and graphs, grafana aids in making sense of the information. All of these factors work in concert to speed up the process of taking an idea from conception to completion and getting it in front of people. As a result, any code that is pushed now goes through the pipeline that we have defined and is automatically built, tested, and deployed sooner leading to multiple deploys to production every day. Once deployed, it is monitored and more user feedback is retrieved, and this cycle repeats on Infinity. Getting feedback from our users, reviewing them, brainstorming, coming up with new ideas and implementing those ideas are now a breeze, and Devops is what it stands for.
DevOps is a group of people, processes, and tools that collaborate to turn ideas into actionable plans and deliver consistently high-quality software.
I will post another blog where devops comes in organizations and how it helps organization etc..


